
하둡
Big Data
1. physical => 수십 Terabyte~ Petabyte 데이터를 갖고 있는 것
2. 소프트웨어 측면에서 보면, 본체 하나의 데이터를 빅데이터를 처리하는 프로세스를 의미
결국 데이터를 수집하는 것 규모가 크니 가공이 필요하다. 가공을 해서 어느 정도 집계를 하는데, 그 다음에 분석이 들어간다. 분석을 해서 시각화 이러한 일련의 과정을 빅데이터라고 한다.
수집 => 가공 => 분석(통계,AI) => 시각화
하둡 수업은 가공을 하는 것이다.
서기 2000년에 인터넷 사용이 활발하게 이용 여러가지 플랫폼이 많아지는데 위기 의식을 느낀 ... 처음에는 좋았는데 수집하는 데이터양이 어마어마한 통계를 내어도 예측이 불가능한 시점..
급한 사람이 우물판다 => 구글 입장에서 제일 급함.. 데이터가 어마어마하니깐... => 내부적으로 프로젝트 회사의 존폐가 걸린 문제 ㅋㅋ => 2003년에 논문 발표 .. 논문이 GFS(구글파일시스템)에 관한 내용 데이터를 한 곳에 모아둘 수 없는 지경에 이르러서 분산되어 저장.. 사용자는 모르고 파일에 어떤 부분을 access .. background에서는 물리적인 파일이 수백대에 나눠져서 데이터 전송 가능 빙글빙글 => 구글파일 시스템 분산 환경으로 사용자가 전혀 못느끼게.. 하나의 작업파일 처럼 느껴지도록 사용자들이 클라우드로 저장해서 사용
2004년에 논문 발표 Map Reduce Framework
수백대의 데이터에서 특정 통계를 뽑을 때 데이터를 추출할 수 있다는 것을 Map Reduce Framework 로 발표
구글 입장에서는 GFS와 Map Reduce Framework을 통해서 가공 측면이 가능해졌다.
유심히 쳐다보던 사람.. 야후에 근무하는 사람.. 나도 만들 수 있을 것 같은데???
자바를 가지고 GFS와 MAP가 지원되는 하둡을 개발... 아들 코끼리 인형이름이 하둡이라 하둡으로 만들었다.
집계 + 분석 + AI 기능 다 가능해졌다. 아파치 소프트제단에 넘겨서 공식 프로젝트로 넘겨짐..
결국 HDFS (하둡파일시스템)을 만들었다. 사용자는 전혀 개의치 않고 여러 데이터를 분산하여 저장 .. 하나의 머신에서 동작할 수 있게 만들었다.!
slack 에서 나눠주신 파일 :)
1. HDFS
● DAS, NAS, SAN에 비해 저사양 서버를 이용하여 스토리지를 구성할 수 있음
● 트랜잭션이 중요한 경우 HDFS는 적합하지 않음 -> 온라인 으로는 적합하지 않음
● 대규모 데이터를 저장, 배치로 처리하는 경우 적합 -> 일괄처리한다.
● HDFS의 목표
1) 장애 복구
a. 빠른 시간내에 장애 감지 및 대처
b. 복제 데이터를 이용한 데이터 유실 방지
2) 스트리밍 방식의 데이터 접근
a. 클라이언트의 요청을 빠른 시간내에 처리 보다는 동일한 시간 내에 더 많은 데이터를 처리 -> 일단 시작이 되면 스트리밍 방식으로 데이터를 밀어넣는다.
b. 이를 위해 랜덤 방식의 데이터 접근을 고려하지 않기 때문에 기존의 인터넷 뱅킹, 쇼핑몰 같은 서비스에 적용하기 부적합 -> 디스크 여기저기 왔다갔다 해야하니깐 지원 X. 순차적으로 데이터를 뽑아준다.
c. 스트리밍 방식으로 데이터에 접근하도록 설계, 클라이언트는 끊김 없이 연속된 흐름으로 데이터에 접근 ->동영상 데이터
2) 대용량 데이터 저장
a. 높은 데이터 전송 대역폭과 하나의 클러스터에서 수백 대의 노드를 지원할 수 있음
대역폭이란? 수도꼭지에서 물을 트는데 동일한 수압일 때 수도꼭지의 크기에 따라 다른거..
b. 하나의 인스턴스에서 수백만개 이상의 파일을 지원
4) 데이터 무결성
a. 한 번 저장한 데이터는 수정할 수 없고 읽기만 가능
b. 이동, 삭제, 복사 가능 c. 하둡 2.0 부터 저장된 파일에 append 기능 지원
2. HDFS Architecture
1) 블록 구조 파일 시스템
a. HDFS에 저장하는 파일은 특정 크기의 블럭으로 나뉘어 분산된 서버에 저장
b. 블록 크기는 기본적으로 128MB로 설정되어 있으며 변경 가능
c. 128MB 보다 작은 데이터는 그 크기에 맞게 블럭이 생성됨
데이터를 가져올 때 블럭 단위로 가져와서 풀어주고 넣어줌.

name node = 마스터하는 역할
각각의 데이터하는게 데이터노드
같은 색깔이 같은 데이터 ..
name node는 어디에 있는지 알 수 있다.
하나가 기계가 작살이 났다고 치면 쓸 수 없으니 다른 곳에서 가져올 수 있고 예비용 데이터도 있어서
데이터가 이미 갖고 있으니 다른 곳에서 가져올 수 있다. copy가 3개 정도 있을 수도
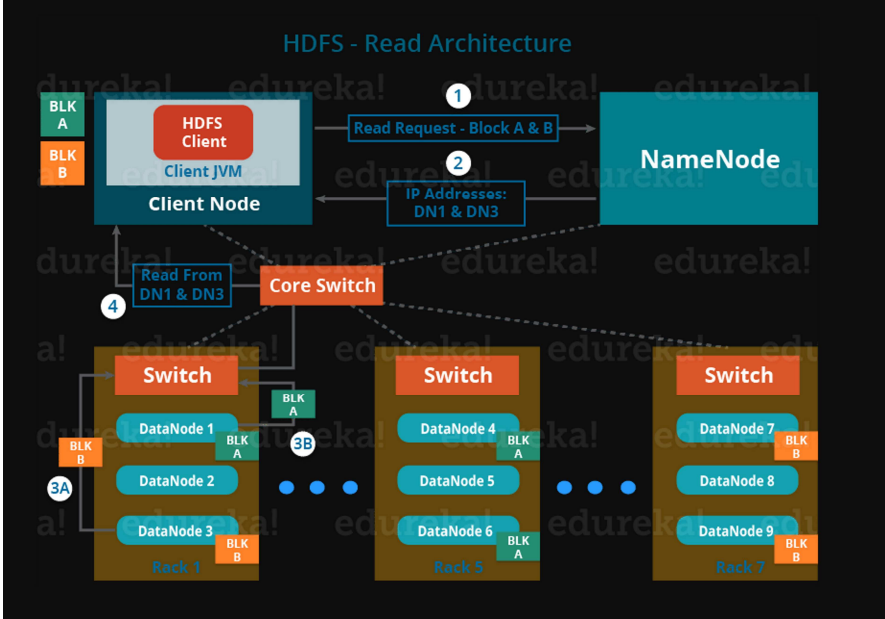
스위치 3개 블럭 A, 블럭 B 요청
데이터가 이미 어디있는지 알고 있음 ip address를 준다.
어느 서버가 어디 있는지 알기 때문에 ip address를 이용해서 접근한다.
datanode의 address를 준다. 해당 data node에 바로 접근
내부적으로 네트워크로 접근 사용자입장에서는 하나의 파일 시스템인 것 처럼 보인다.
라우팅경로 알고리즘이 있지만 static하게 정해놓고 사용한다.
1) 네임 노드, 데이터 노드
a. Master - Slave 아키텍쳐 ( 네임 노드 - 데이터 노드)
2) 네임 노드
● 메타데이터 관리 -데이터에 대한 데이터
파일 시스템을 유지하기 위한 메타데이터 관리 메타데이터는 파일 시스템 이미지(파일명, 디렉터리, 크기, 권한 등)와 파일 에 대한 블록 매핑 정보로 구성
클라이언트에게 빠르게 응답할 수 있게 메모리에 전체 메타데이터를 로딩 - 로딩시켜둔 상태로 대기 메모리를 던져줌
● 데이터 노드 모니터링
데이터 노드는 네임 노드에게 매 3초 마다 heartbeat 메시지를 전송 - 3초마다 주기적으로 보냄 심장이 주기적으로 뛰듯이..
정보를 네임 노드에게 보낸다..
heartbeat는 데이터 노드 상태 정보와 저장되어 있는 블럭의 목록으로 구성
네임노드는 heartbeat 를 이용해 데이터 노드의 실행 상태와 용량을 모니터 일정 시간 동안 heartbeat 가 도착하지 않으면 네임 노드는 해당 데이터 노드를 장애로 판단 - 임계시간동안 안오면 장애가 생겼다고 판단.. 예비로 남겨둔 데이터 활성화 시킨다. 복사하거나 명령을 한다.
● 블록 관리
장애가 발생한 데이터 노드를 발견하면, 해당 데이터 노드의 블럭을 새로운 데이터 노드로 복제 용량이 부족한 데이터 노드가 있다면 상대적으로 여유가 있는 데이터 노드 로 블럭을 이동 블럭의 복제
본 수 관리(복제 본 수와 일치하지 않는 블럭이 발견되면 추가 로 블럭을 복제 또는 삭제)
● 클라이언트의 요청 접수
클라이언트가 HDFS에 접근하려면 반드시 네임 노드에 먼저 접속
HDFS에 파일을 저장하는 경우 기존 파일의 저장 여부와 권한 확인 절차를 거쳐 승인 처리
HDFS에 저장되 파일을 조회하는 경우 블럭의 위치 정보를 반환
3) 데이터 노드
● 클라이언트가 HDFS에 저장하는 파일을 로컬 디스크에 유지
● 로컬 디스크에 저장되는 파일은 실제 데이터가 저장되어 있는 raw 데이터 파 일과 checksum 이나 파일 생성 일자와 같은 메타 데이터가 설정된 파일

1) 파일 저장 요청
a. 하둡은 FileSystem 이라는 추상클래스에 일반적인 파일 시스템을 관리하기 위한 메서드를 정의, 이 추상클래스를 상속받아 각 파일 시스템에 맞게 구현된 다양한 파일 시스템 클래스를 제공, HDFS에 파일을 저장하는 경우에 파일 시스템 클래 스 중 DistributedFileSystem 클래스를 사용, 클라이언트는 DistributedFileSystem 클래스의 create 메서드를 호출해 스트림 객체를 생성
b. DistributedFileSystem 은 클라이언트에게 반환할 스트림 객체로 FSDataOutputStream객체를 생성, FSDataOutputStream은 데이터노드와 네임노 드간 통신을 관리하는 DFSOutputStream 클래스를 wrapping 하는 클래스임, DistributedFileSystem은 DFSOutputStream을 생성하기 위해 FSDataOutputStream의 create 메서드를 호출
c. FSDataOutputStream은 DFSOutputStream을 생성, 이 때 DFSOutputStream은 RPC통신으로 네임노드의 create 메서드 호출, 네임노드는 클라이언트의 요청이 유효한지 검사를 진행, 이미 생성된 파일이거나 권한에 문제가 있거나, 현재 파일 시스템의 용량을 초과한다면 오류가 발생, 네임노드는 파일 유효성 검사 결과가 정상일 경우 파일 시스템 이미지에 해당 파일의 엔트리를 추가, 네임노드는 클라 이언트에게 해당 파일을 저장할 수 있는 제어권을 부여
d. 네임노드의 유효성 검사를 통과했다면 DFSOutputStream객체가 정상적으로 생 성, DistributedFileSystem은 DFSOutputStream을 래핑한 FSDataOutputStream을 클라이언트에게 반환
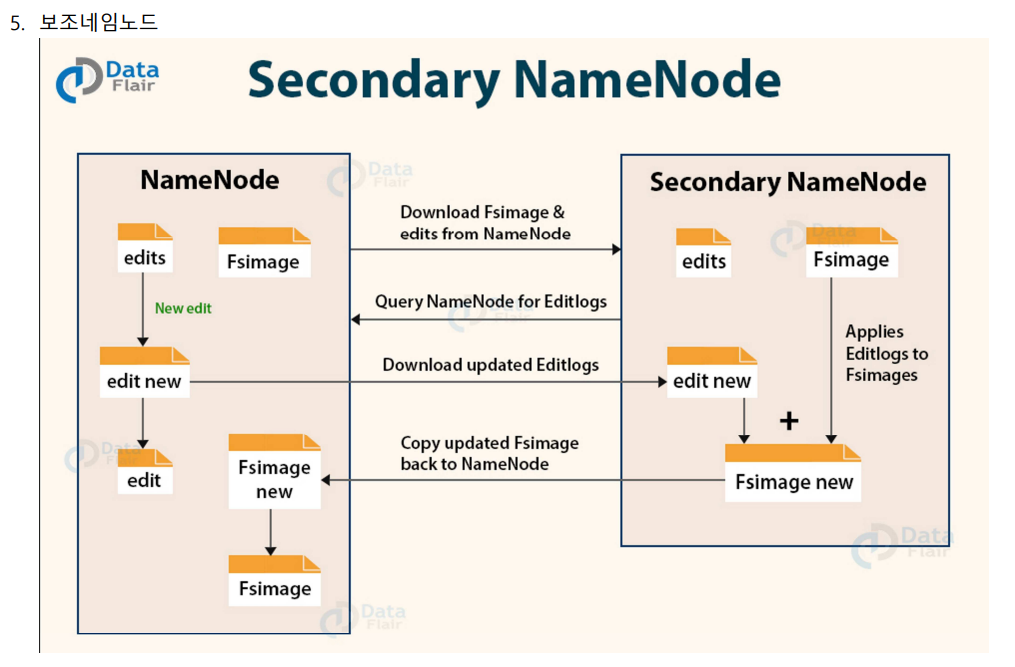
결론만 얘기하면, 데이터가 추가되고 삭제된다. 현재의 상태의 데이터 매핑정보를 데이터가 갖고있다.
항상 메모리가 일관성있게 가지게 될 수 있는가? 보조네임노드가 도와준다. 반드시 있어야한다.
항상 쿼런트 이미지 메모리에 가질 수 있게 도와준다.
ex) 조수석에 있는 사람이 네비를 봐주는 것 처럼
slack 참조
YARN 구조
아파치 하둡 얀은 리소스 관리와 컴포넌트 처리를 분리한 하둡 2.0에 도입된 아파치 소프트웨어 재단의 서브 프로젝트입니다. 얀은 맵-리듀스의 차세대 기술로서 맵-리듀스의 확장성과 속도문
nive.tistory.com
기존 1.0 움켜쥔 상태 하둡에서 뭘 빼갈 수 있으므로.. yarn 리소스 별도로 띄어내자.. 얀에서 요청하고 받는 프로그램을 만들자. 맵-리 듀스의 확장성과 속도문제를 해소.. 하둡 위에 얀 얀을 통해서 요청할 수 있게 만들었다.

YARN의 구조 얀(YARN)은 크게 리소스 매니저(Resource Manager), 노드 매니저(Node 03-01 Yarn), 애플리케이션 마스터(Application Master), 컨테이너(Container)로 구성되 어 있습니다
① 리소스 매니저(Resource Manager)
클러스터 전체를 관리하는 마스터 서버의 역할을 담당하며, 응용 프로그램의 요청을 처리합니다. 리소스 매니저는 클러스터에서 발생한 작업을 관리하는 애플리케이션 매니저(Applications Manager)를 내장하고 있으며, 응용 프로그램들 간의 자원 (resource) 사용에 대한 경쟁을 조율합니다. 여기서 말하는 자원이란 CPU, 디스크 (disk), 메모리(memory)등을 의미합니다.
딸랑 1개
② 노드 매니저(Node Manager)
노드당 하나씩 존재하며, 슬레이브 노드(slave node)의 자원을 모니터링 (monitoring) 하고 관리하는 역할을 수행합니다. 노드 매니저는 리소스 매니저의 지 시를 받아 작업 요구사항에 따라서 컨테이너를 생성합니다.
데이터 노드마다 노드 매니저가 들어가있음.
③ 애플리케이션 마스터(Application Master)
노드 매니저와 함께 번들로 제공되며, 작업당 하나씩 생성이 되며, 컨테이너를 사용 하여 작업 모니터링과 실행을 관리합니다. 또한, 리소스 매니저와 작업에 대한 자원 요구사항을 협상하고, 작업을 완료하기 위한 책임을 가집니다.
④ 컨테이너(Container)
CPU, 디스크(Disk), 메모리(Memory) 등과 같은 속성으로 정의됩니다. 이 속성은 그 래프 처리(Graph processing)와 MPI(Message Passing Interface: 분산 및 병렬 처리에서 정보의 교환에 대해 기술하는 표준)와 같은 여러 응용 프로그램을 지원하는데 도움이 됩 니다. 모든 작업(job)은 결국 여러 개의 작업(task)으로 세분화되며, 각 작업(task)은 하나의 컨테이너 안에서 실행이 됩니다. 필요한 자원의 요청은 애플리케이션 마스터 (Application Master)가 담당하며, 승인 여부는 리소스 매니저(Resource Manager)가 담당합니다. 컨테이너 안에서 실행할 수 있는 프로그램은 자바 프로그램뿐만 아니 라, 커맨드 라인에서 실행할 수 있는 프로그램이면 모두 가능합니다.

데이터 노드 어디가에 어플리케이션 마스터가 생성 작업당 하나씩 생성.. 얘한테 요청을 해놓고 기다린다. 얘가 다 알아서 처리해주니깐~ 확장성이 높아짐 얀을 통해서 HDFS를 사용할 수 있다.

라인 단위로 split -> 단어별로 쪼갠다.(map작업) -> 같은단어가 있으면 모이게 섞는다. -> 데이터를 줄여준다. Reduce 작업 -> input에 대한 결과
구글같은 회사는 수천개 .. 이 작업을 한다고 치면, 수많은 데이터 노드에서 매핑 작업이 별도로 셔플 작업이 .. reduce... 결과를 뽑아줌...
자바에서 사용하는 데이터 타입 X 사용못함..
하둡에서 기본적으로 제공하는 데이터 타입
● BooleanWritable
● ByteWritable
● DoubleWritable
● FloatWritable
● IntWritable
● LongWritable
● TextWrapper (UTF8 형태의 문자열)
● NullWritable (데이터 값이 필요 없을때

규약이 있어야...... 약속 = 프로토콜

https://github.com/protocolbuffers/protobuf/releases/tag/v2.5.0

링크 주소 복사

root 계정
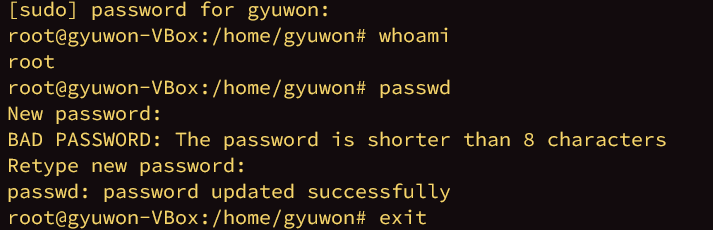
root 계정 setting sudo 권한이 있을 때 사용할 수 있다.







version 확인

https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
Apache Downloads
We suggest the following site for your download: https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz Alternate download locations are suggested below. It is essential that you verify the integrity of the downloaded file using the PGP si
www.apache.org
https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz 링크 주소 복사


jdk 1.8 설치


맨 마지막 페이지에 추가해준다.
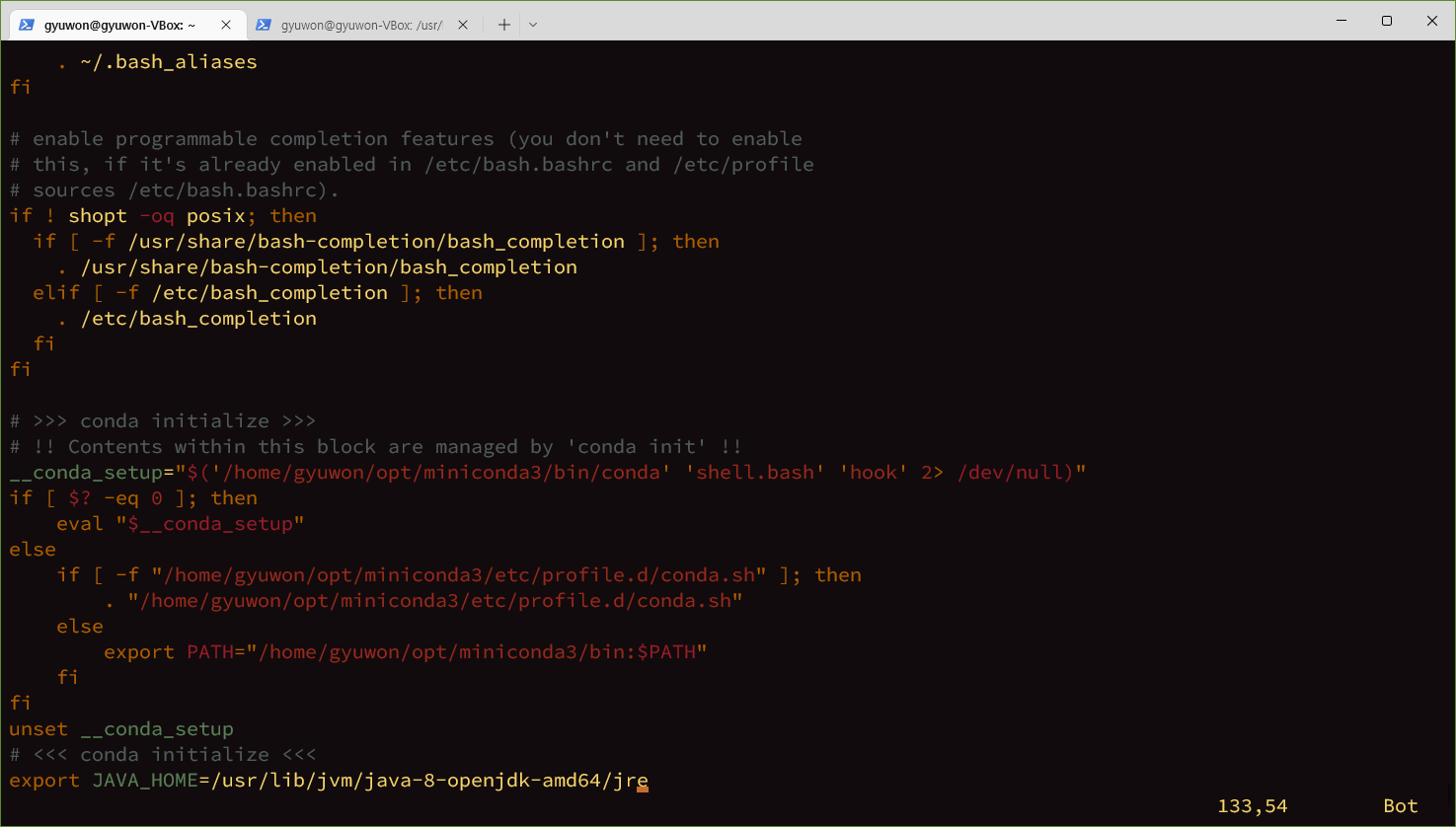
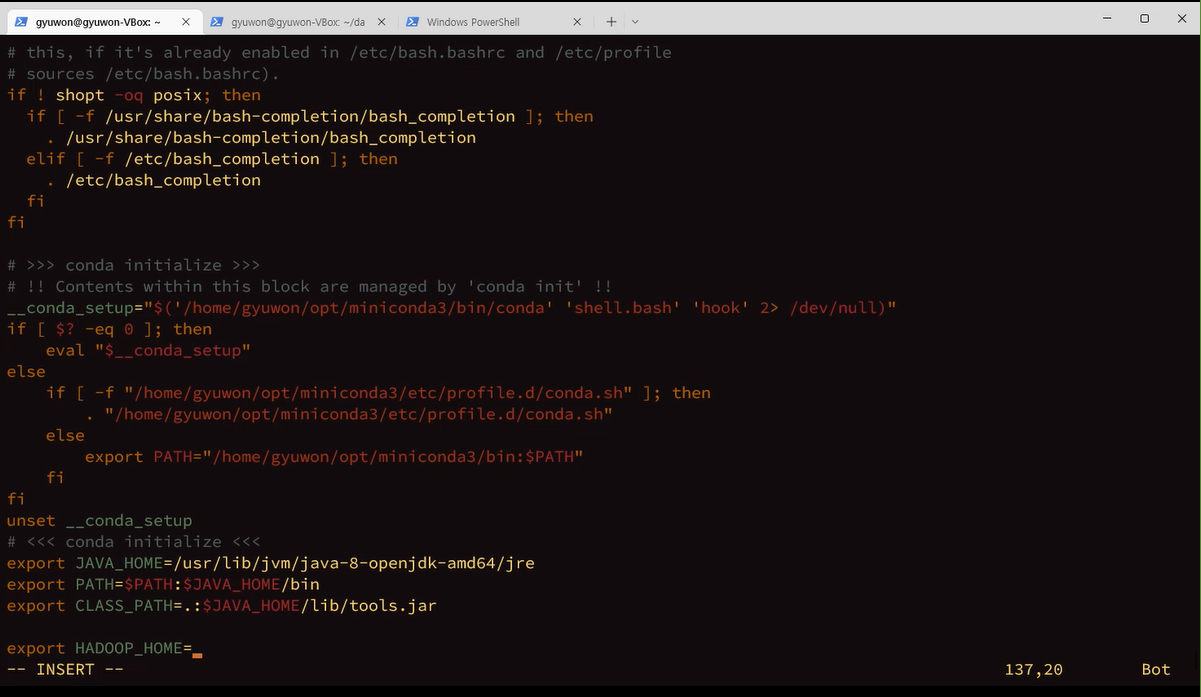
export 현재 쉘에다가 환경변수 설정
현재 shell에서 child process 생성할 때 그대로 환경변수 넘겨주고 싶을 때 export를 쓴다.
프로세스를 적용하면 적용이 안되니깐 자식 프로세스한테 넘겨주고 싶다. export

:wq

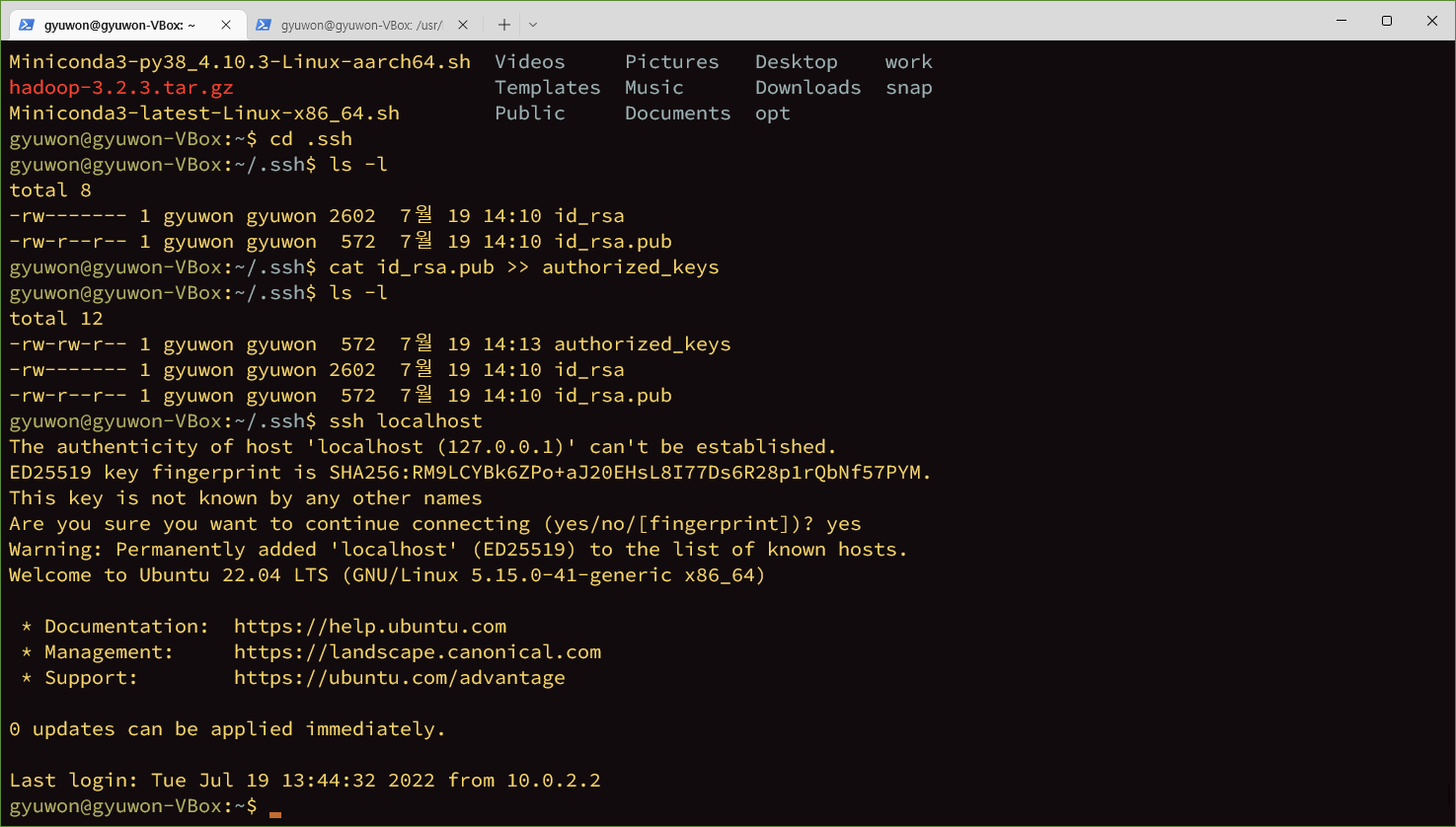
네임노드 통신


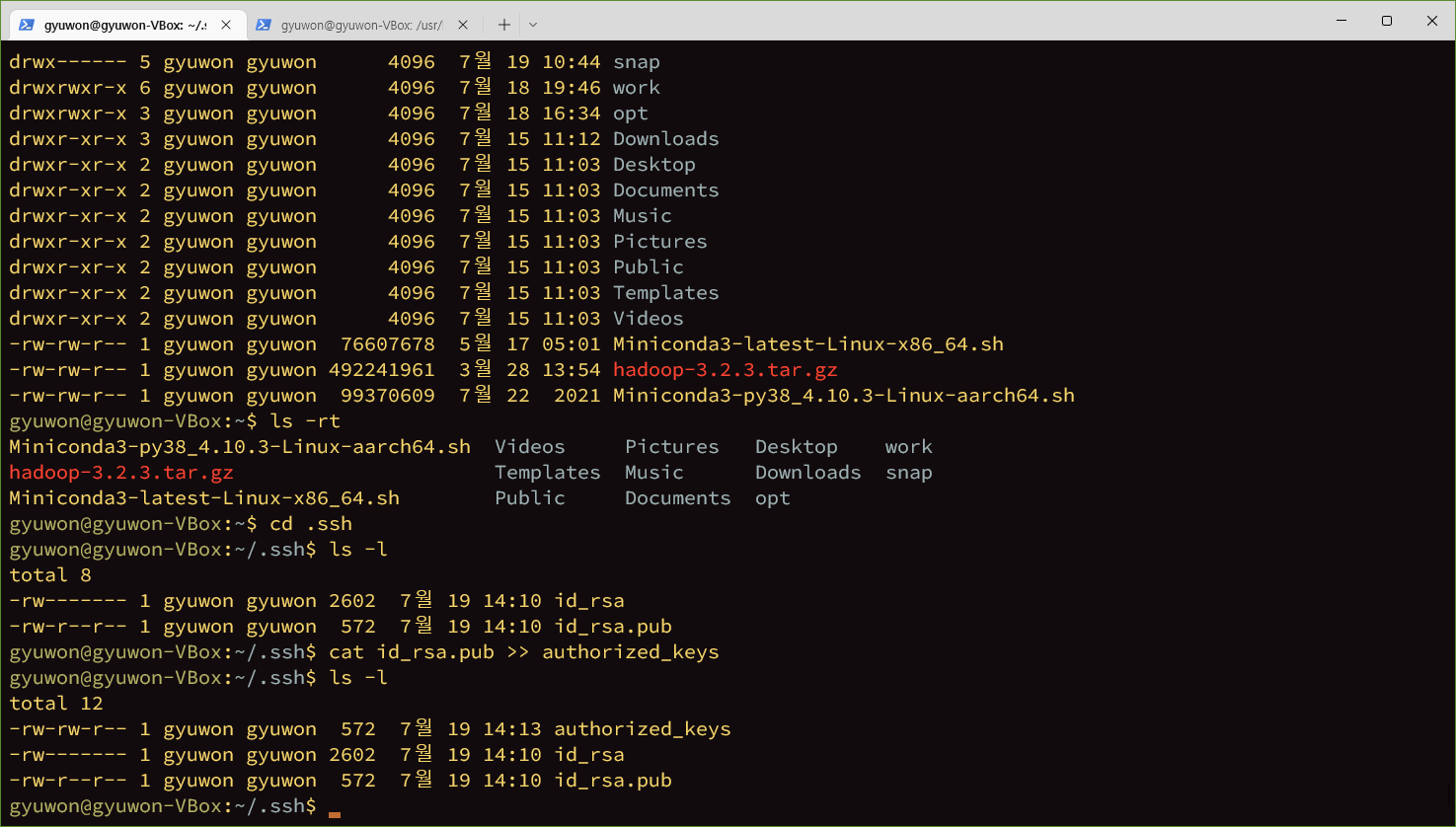
개인키
공용키 pub 키 남에게 주는 것
pub키 내용을 남이 볼 수 있도록 허용
>>
여러군데 있으면 오버라이드될 수 있으니 하나만 써준다.


풀어주기



/HADOOP_PID 검색..
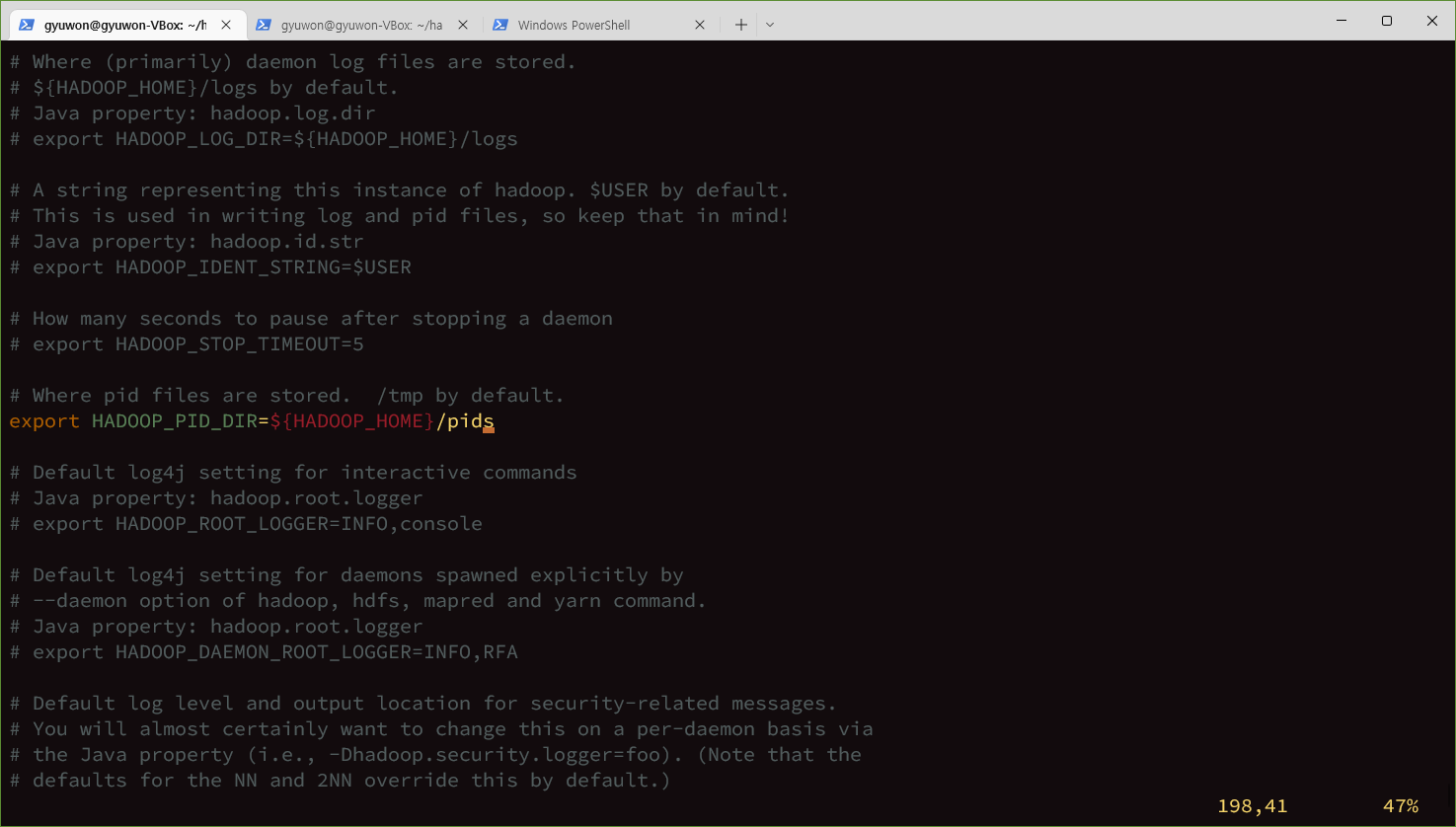
고쳐주기


masters에 localhost 적고 나온다.
그냥 나온다.. workers

localhost에 9000번으로 접속해라.

1copy만 유지해라 dfs.replicaiton

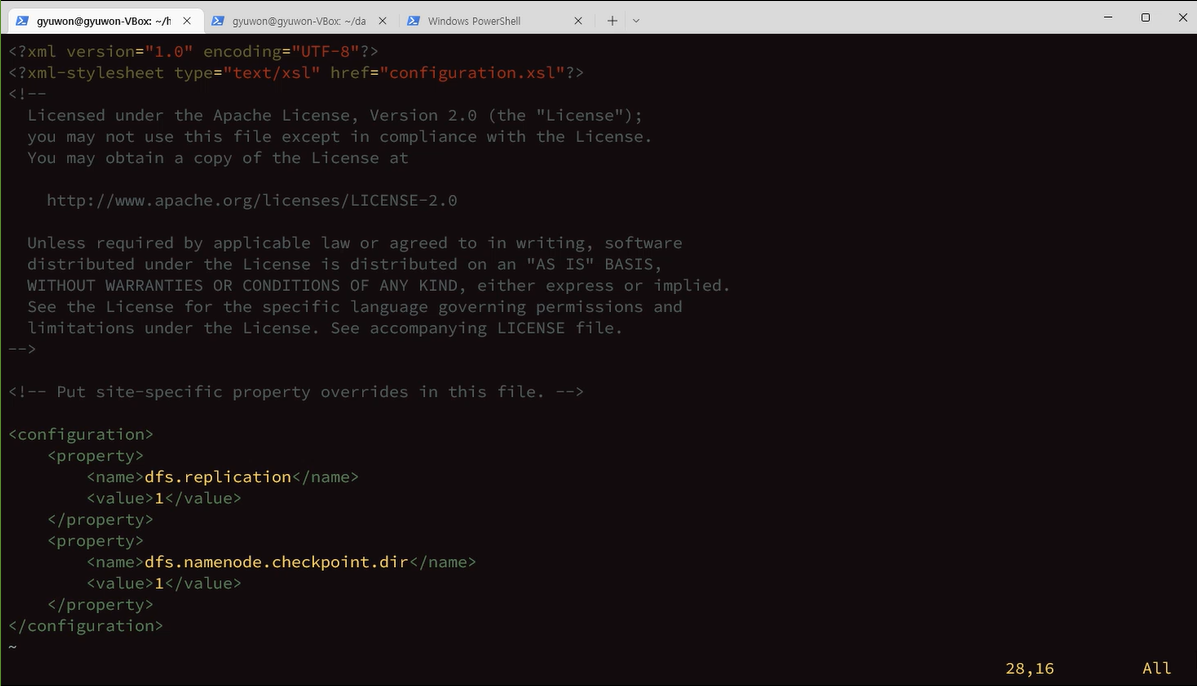

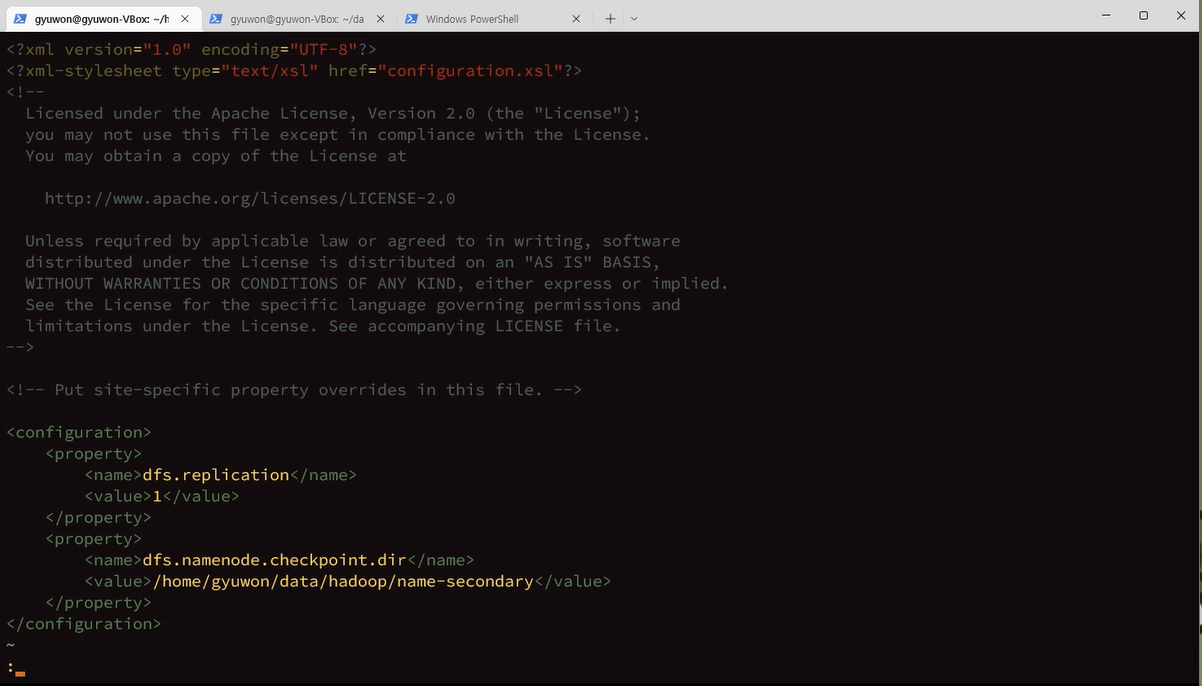
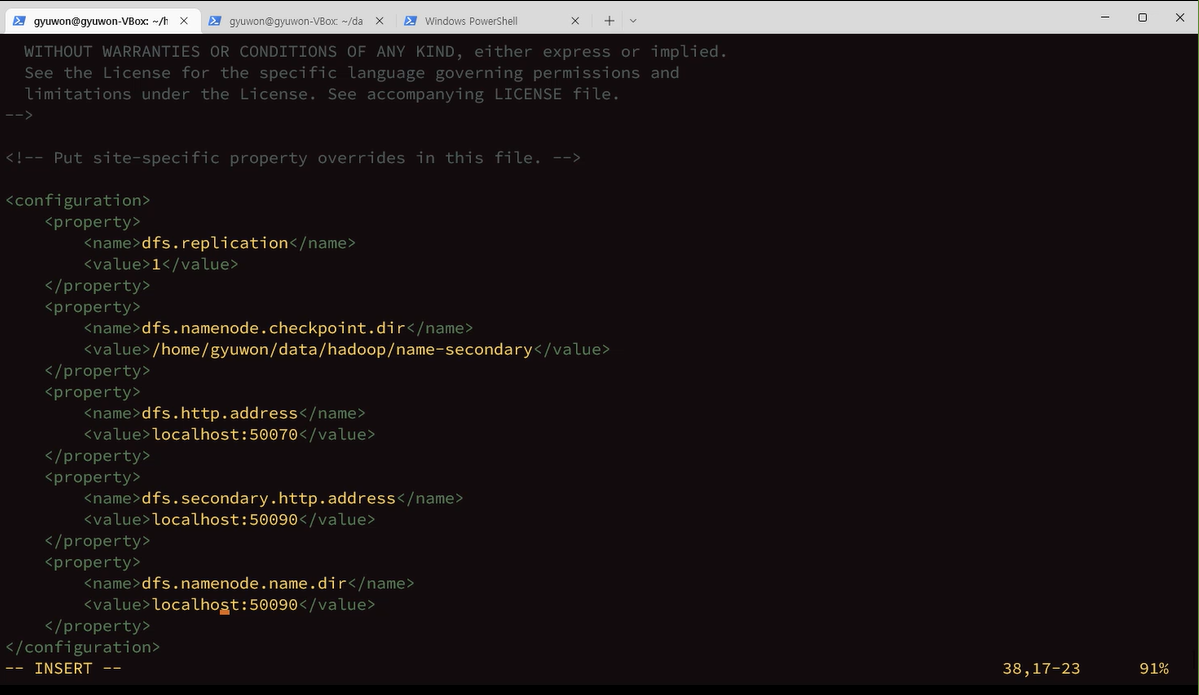

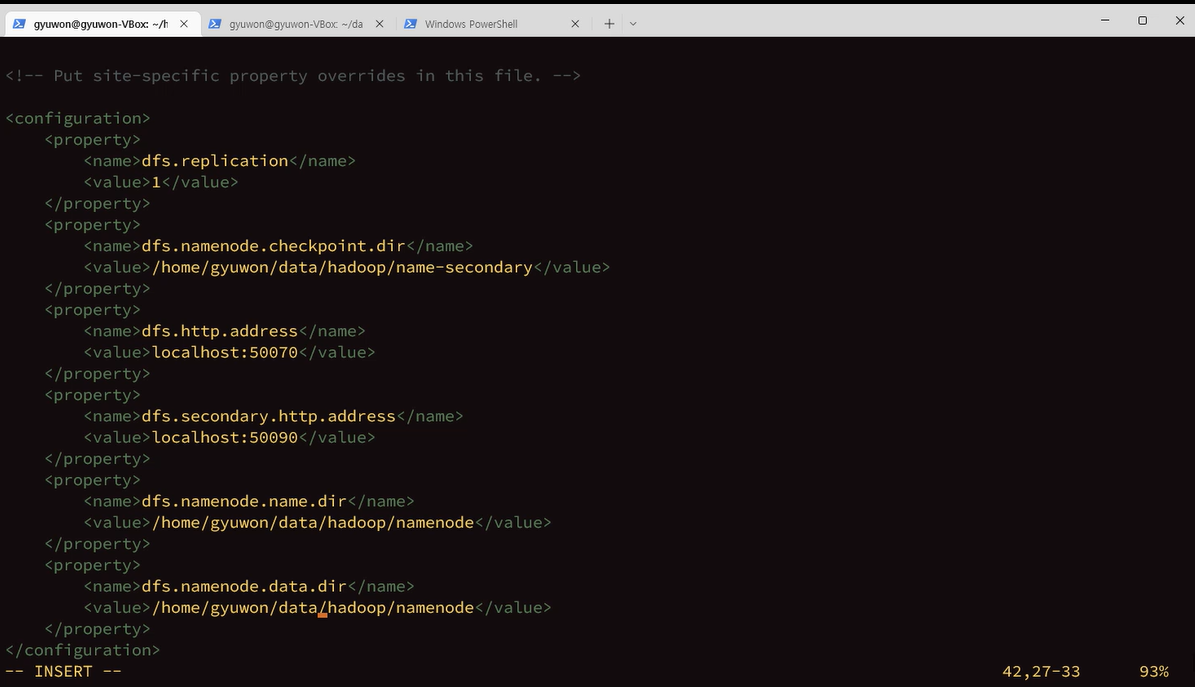







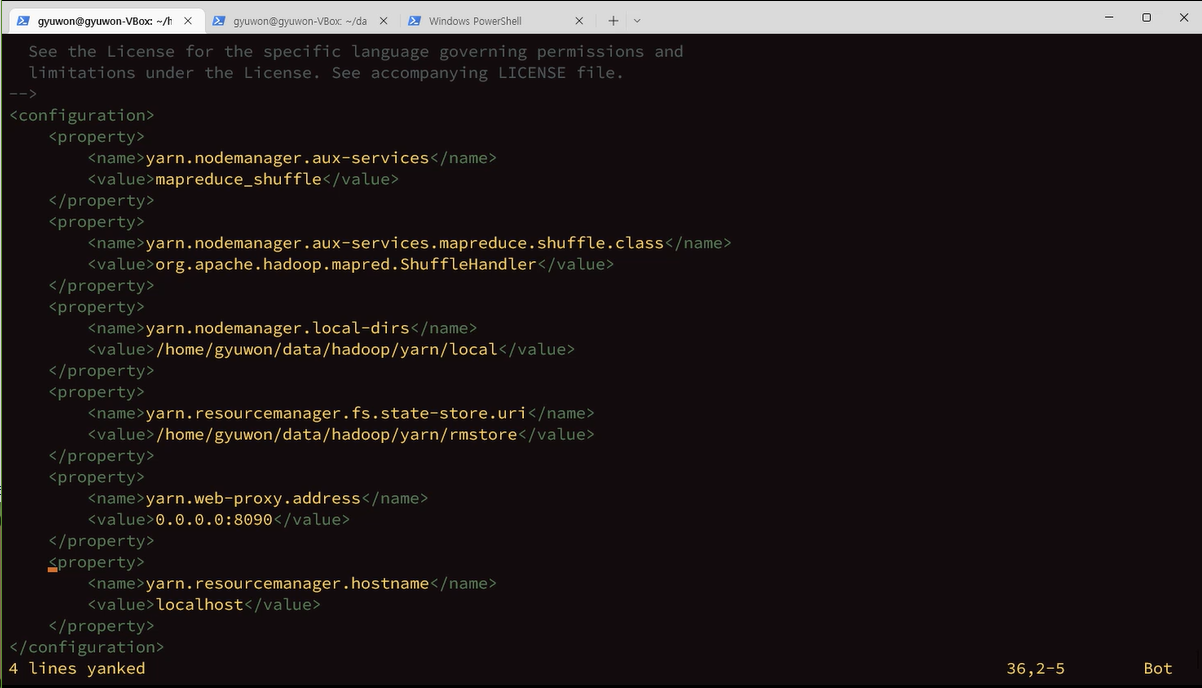


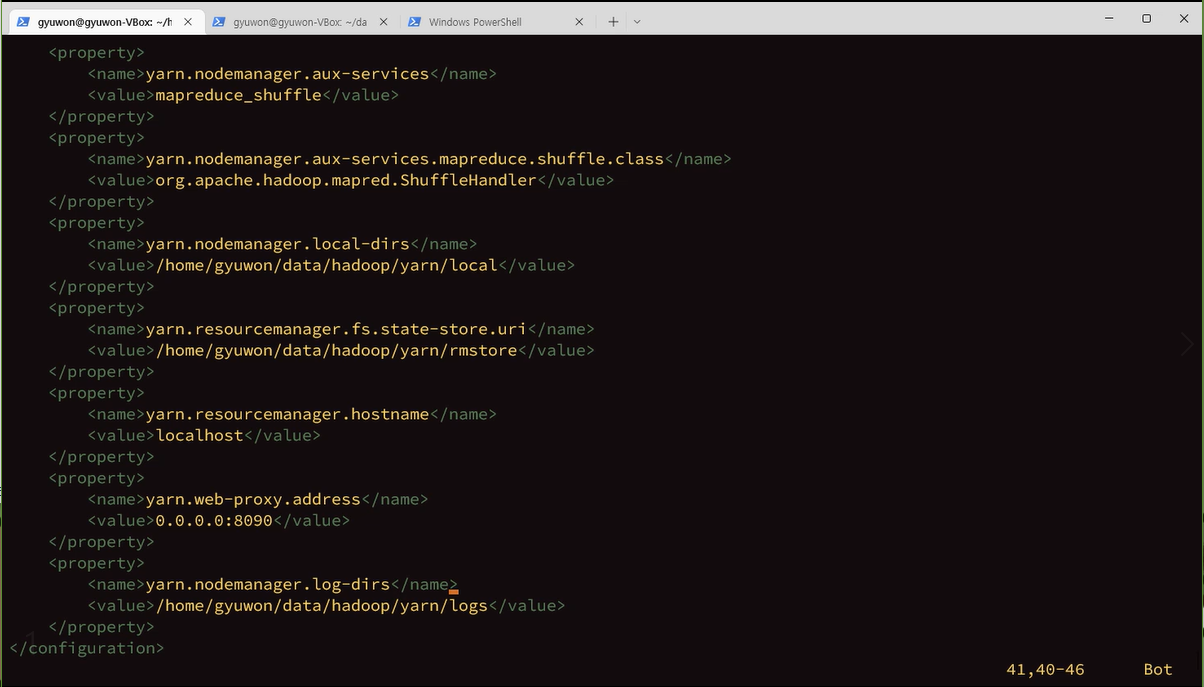
am = application manager
aux-services 부가서비스 shuffle를 yarn한테 제공
aux : 주유기기 꼽는 곳
보조자

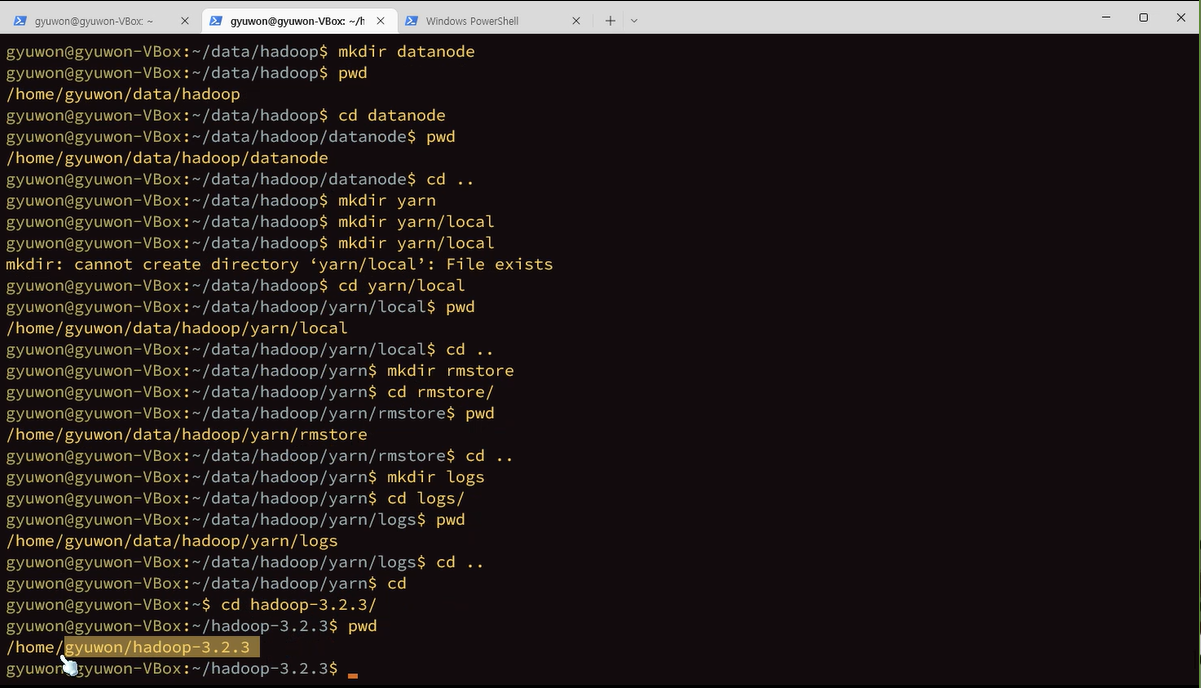




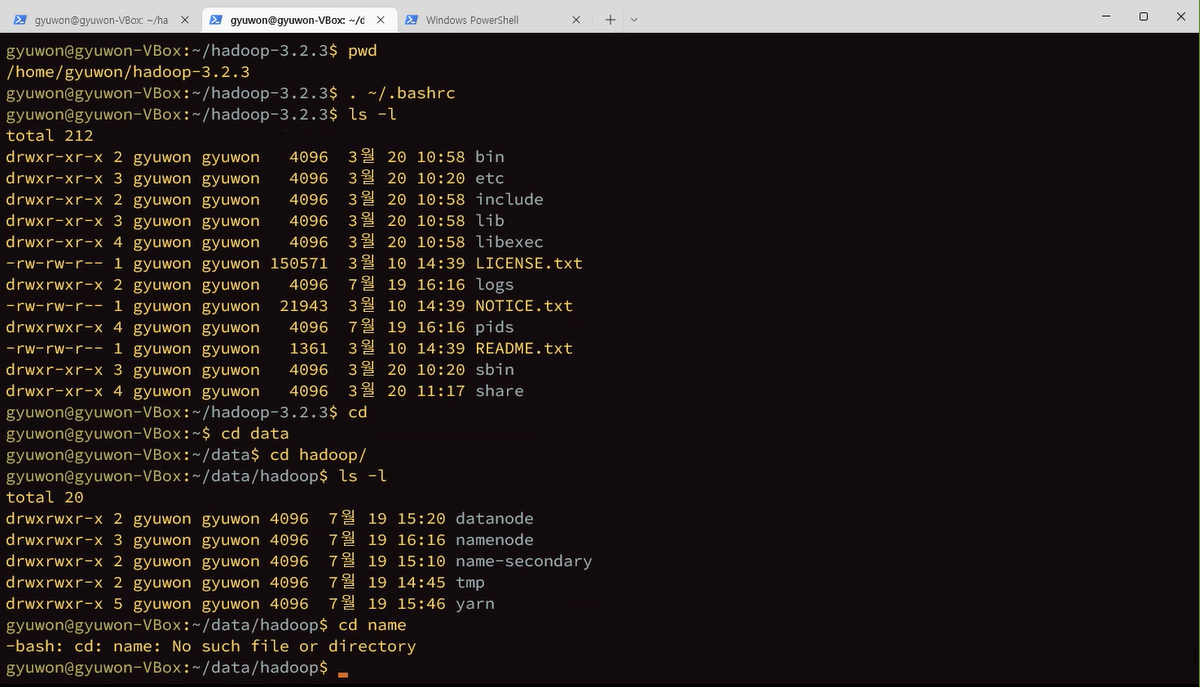
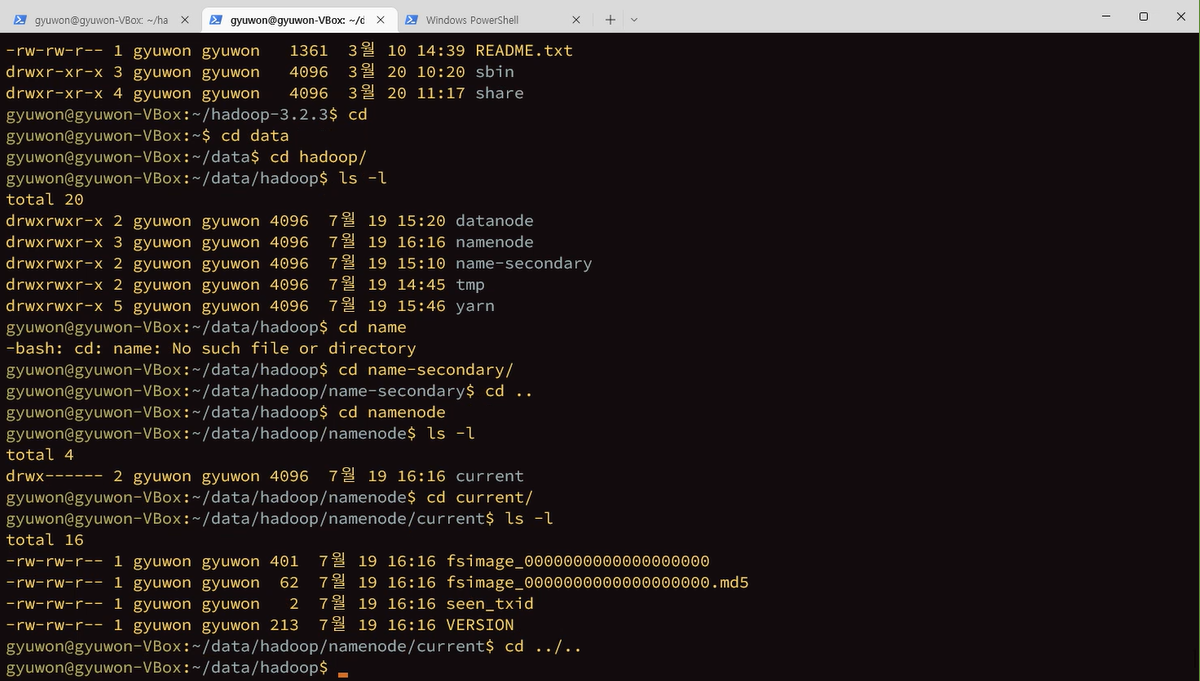
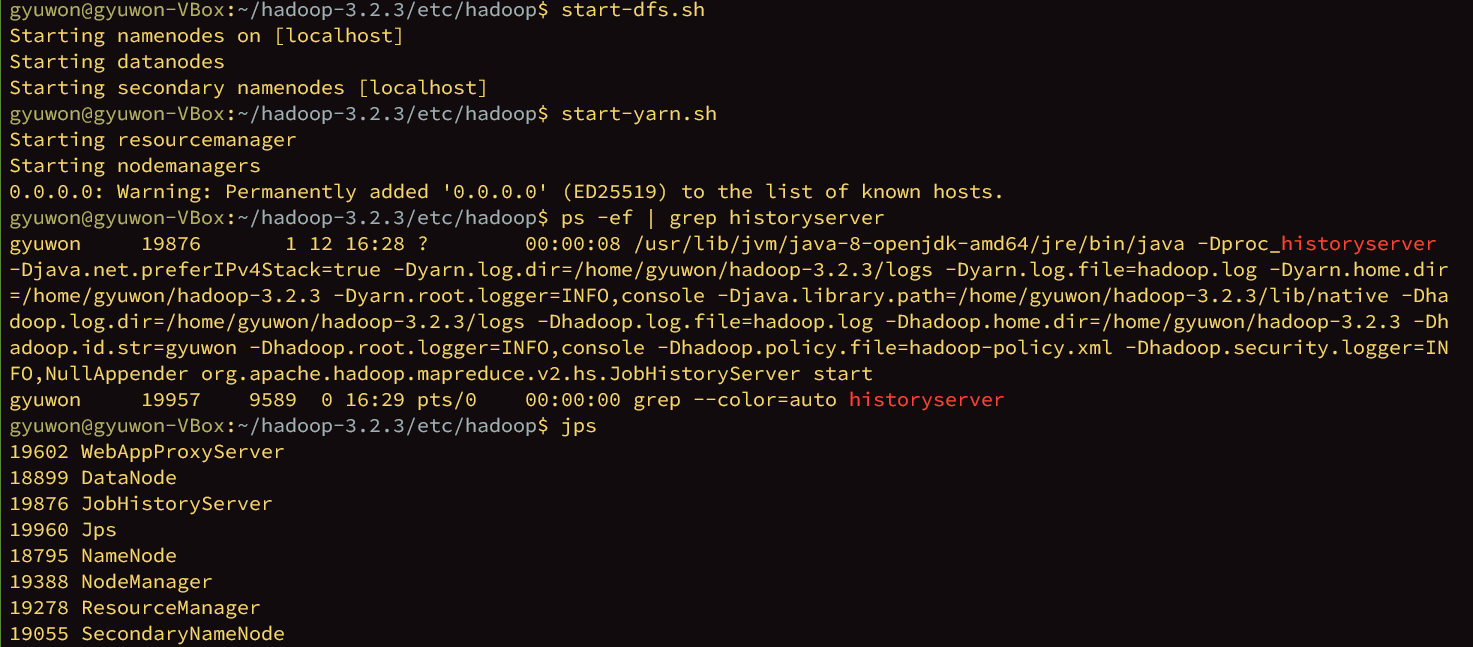
포멧은 첫번째로 한번만 한다.
$hdfs namenode-format

format하고 성공인거 확인






'비트교육 > HADOOP' 카테고리의 다른 글
| [26일차] hadoop eco system/hive 설치/HiveQL사용하기 (0) | 2022.07.26 |
|---|---|
| [25일차] DelayCountWithMultipleOutputs.java (0) | 2022.07.25 |
| [24일차] driver 패키지에 ArrivalDelayCount/ DelayCount/ DelayCounterWithCounter/ DelayCountWithCounterTwo 작성하기 (0) | 2022.07.21 |
| [23일차] Hadoop WordCount . DepartureDelayCount (0) | 2022.07.20 |