2022.07.04
Studio 3T for MongoDB

Upsert 있으면 업데이트 없으면 insert
내부적으로 upsert를 제공한다.

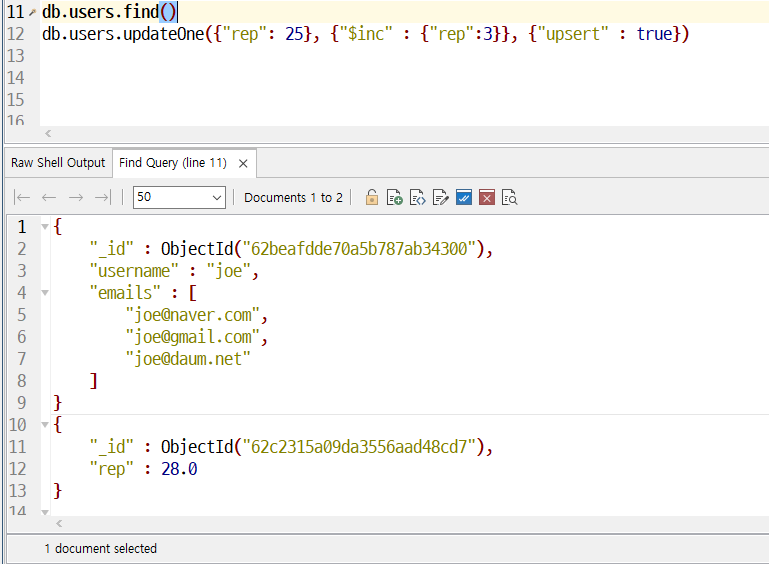
$inc 연산자는 이미 존재하는 키의 값을 변경하거나 새 키를 생성하는 데 사용한다.
분석, 분위기, 투표 등과 같이 자주 변하는 수치 값을 갱신하는 데 매우 유용하다.
3이 나올 것 같지만,, 28이 나온다.
이유는? 동작 메커니즘이 있다.
upsert니깐 없으니 추가하고 있으니 업데이트해주는
rep가 25인 새로운 도큐먼트를 만들고 3만큼 증가시켜 rep는 28이 된다.
갱신 입력을 지정하지 않으면 {"rep" : 25}는 어떤 도큐먼트와도 일치하지 않으며 25일도 발생하지 않는다.



똑같이 들어가는 거 확인

gift 필드 추가해서 삽입한 도큐먼트 세개에 각각 gift 필드가 추가되는 걸 알 수 있다.
조건에 맞는 도큐먼트를 모두 수정하려면 updateMany를 사용한다.

find에다가 옵션을 줄 수 있는데
projection / collection
키의 값만 원할 때


projection 뭘 빼고 나와라 뭐만 출력해라 라는 의미
특정한 키/ 값 쌍을 제외한 결과를 얻을 수 있다.
필요없는 건 제외시킨다. "_id" 반환을 제외
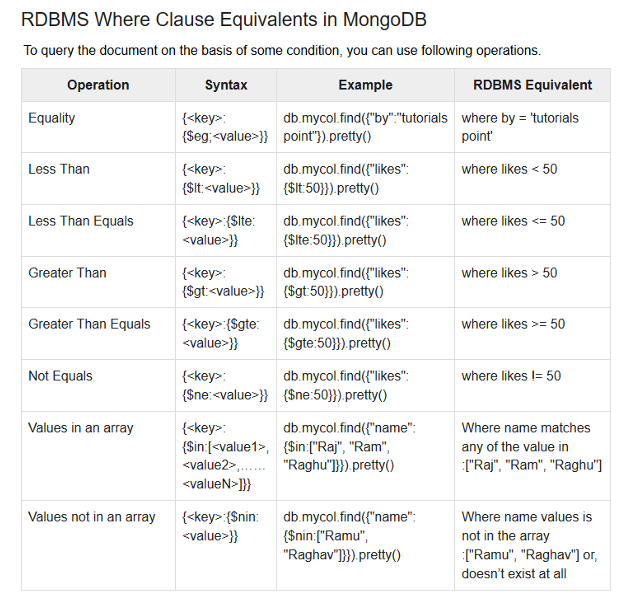
조건연산자
gte는 >= 이다.
age가 18이상 30이하인 document를 모두 찾아낸다.

slack 에서 받은 조건연산자 표


조건 반대라서 하나도 안나온다

not은 메타조건절이며 어떤 조건에도 적용할 수 있다.
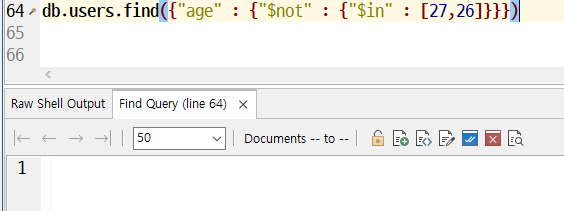


두개의 차이를 기억해두도록 하자 ,, 없으니깐 없는 값을 제외한 나머지가 다 나오게 된다.


값이 null인 키만 찾고 싶으면 null 이 값을 쿼리하고 , $exists 조건절을 사용해 null 존재 여부를 확인하면 된다.
y는 null 값이 있어서 나오고 x는 없어서 나오지 않는다.


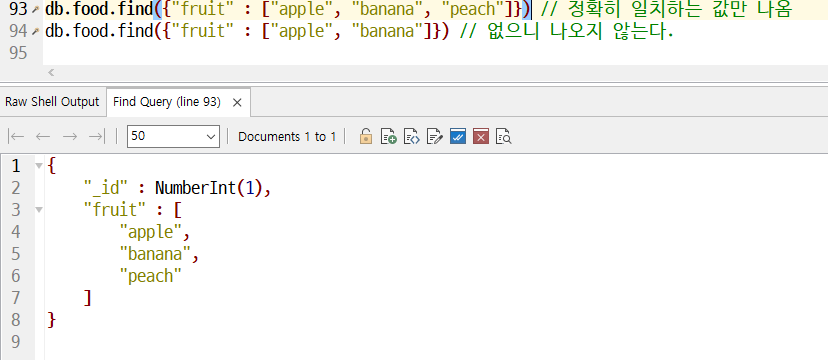
배열로 주면 정확하게 일치해야 나온다.

순서가 바뀌면 다른거라 나오지 않는다.

- apple 과 banana가 들어있는 모든 배열이 다 튀어나온다.
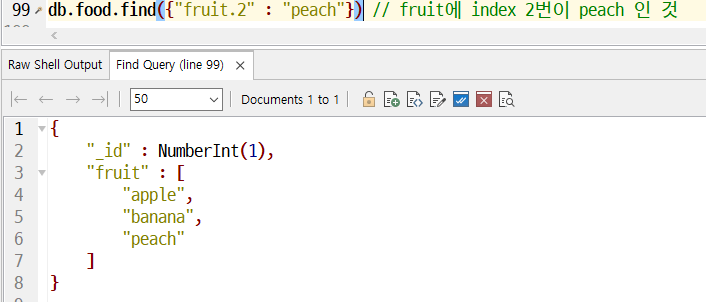
- fruit에 index 2번이 peach인 배열 찾기

- size 특정 크기의 배열을 쿼리하는 유용한 조건절
5) $slice
find 의 두번째 인자는 반환값에 대한 것
"$slice" 는 반환되는 배열의 subset을 얻게 한다.
배열의 처음 10개 항목 추출(-10 : 마지막 10개)
db.blog.posts.findOne(조건, {"comments" : {"$slice" : 10}})
처음 23개 항목 건너뛰고 24번째 부터 10개
db.blog.posts.findOne(조건, {"comments" : {"$slice" : [23, 10]}})


마지막만 배열

특정한 스칼라값과 배열 혼용하는 건 아예 안하는 게 좋다.
a) 먼저 10 보다 큰 값을 가진 도큐먼트를 찾는다. ==> {"x" : 15}, {"x" : 25}, {"x" : [5, 25]}
b) 이 결과에서 20보다 작은 값을 가진 도큐먼트를 선택한다. ==> {"x" : 15}, {"x" : [5, 25]}
즉, {"x" : [5, 25]} 값은 각 항목으로 위 두 조건을 모두 만족하기 때문에 선택된다.내장 도큐먼트 쿼리하기


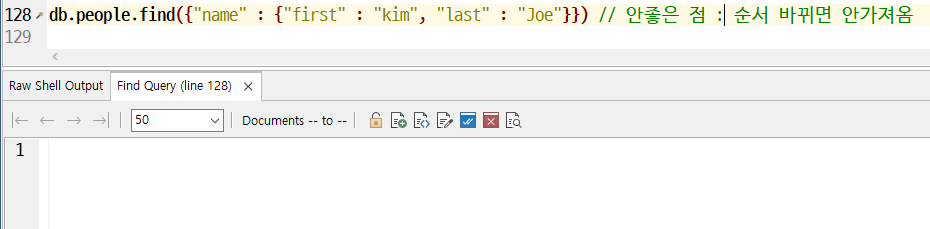




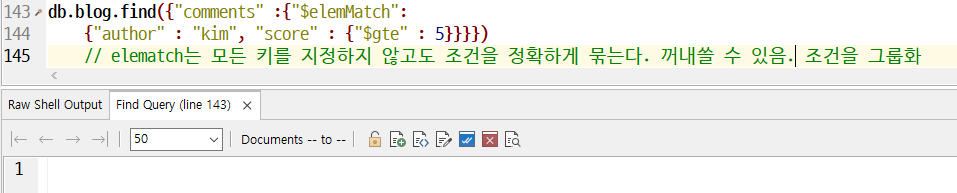
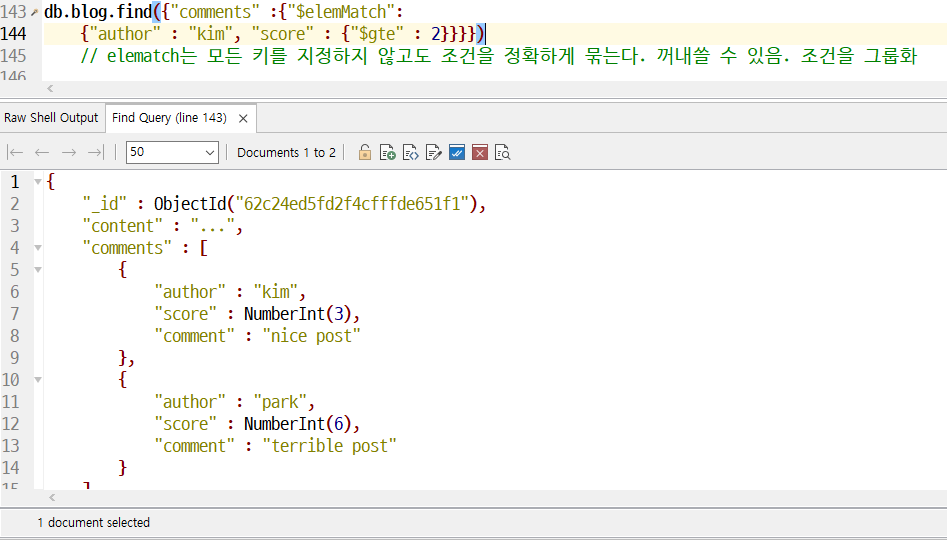
- 배열로 비교할 때에는 elematch를 쓴다. 내장 도큐먼트에서 2개 이상의 키의 조건일치 여부를 확인할 때만 필요하다.

- 새로운 값 insert
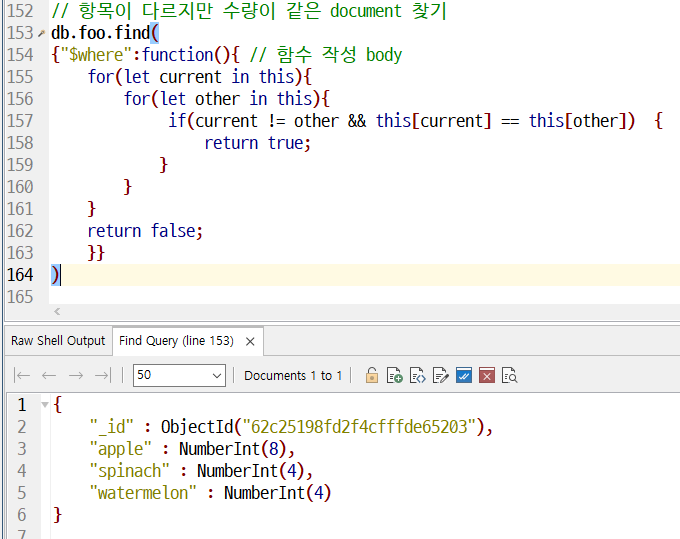
$where 쿼리
where라는게 있는데 where안에 javascript 소스코드를 사용할 수 있고
보안상의 이유로 못쓰게 막아둔다. 코드의 의미는 몰라도 된다.
1) Limits, Skips, Sorts
3개의 결과만 반환
> db.c.find().limit(3)
.
처음 3개의 결과를 스킵하고 나머지 반환, 결과가 3개 이하면 아무것도 반환되지 않는다.
> db.c.find().skip(3)
**
일반적으로 작은 양의 skip을 사용하는 것은 문제가 없다.
그러나 대량 skip을 사용하게 되면 일단 모든 skip할 도큐먼트를 find 한 후
skip을 수행하기 때문에 전체적으로 성능이 느려진다.
그러므로, 대량의 skip은 피해야 한다.
username으로 ascending, age로 descending
> db.c.find().sort({username : 1, age : -1})
쇼핑몰에서 TV를 높은 가격순으로 50개 검색
> db.stock.find({"desc" : "TV"}).limit(50).sort({"price" : -1})
CH7 집계 프레임워크 P.223
- 1개이상의 STAGE 생성 각 STAGE를 거치면서 단계를 생성
각 STAGE -> STAGE 올라가는게 파이프라인 구조
일치 match , 선출 projection , 정렬 sort, 건너뛰기 skip, 제한 limit
aggregate는 집계 쿼리를 실행할 때 호출하는 메서드
집계를 위해 집계 파이프라인을 전달하는데, 파이프라인은 도큐먼트를 요소로 포함하는 배열
match 단계에서는 컬렉션에 대해 필터링하고 결과 도큐먼트를 한 번에 하나씩 선출 단계로 전달한다.
선출 단계는 작업을 수행하고 도큐먼트 모양을 변경 후 출력을 파이프라인에서 다시 우리에게 전달한다.
터미널에서 사용하기!
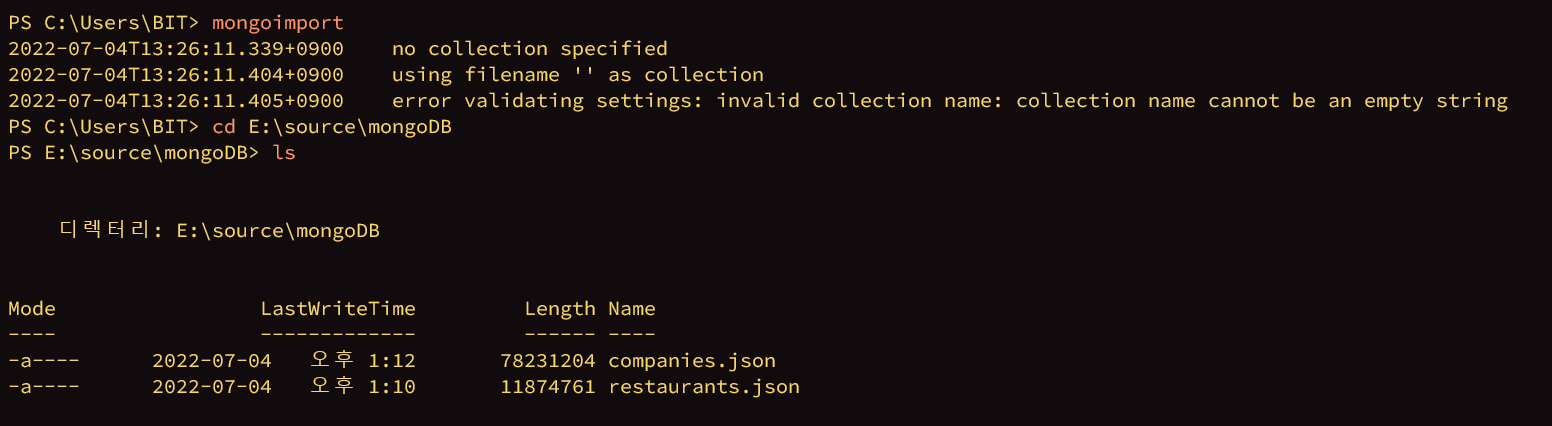

sample_db 사용하는 거 확인


documents 433개 확인


데이터 살펴보기 데이터 구조 파악..

_id 필드는 제외하고 나머지 조건 출력

10개의 도큐먼트를 건너뛰고(skip) 출력
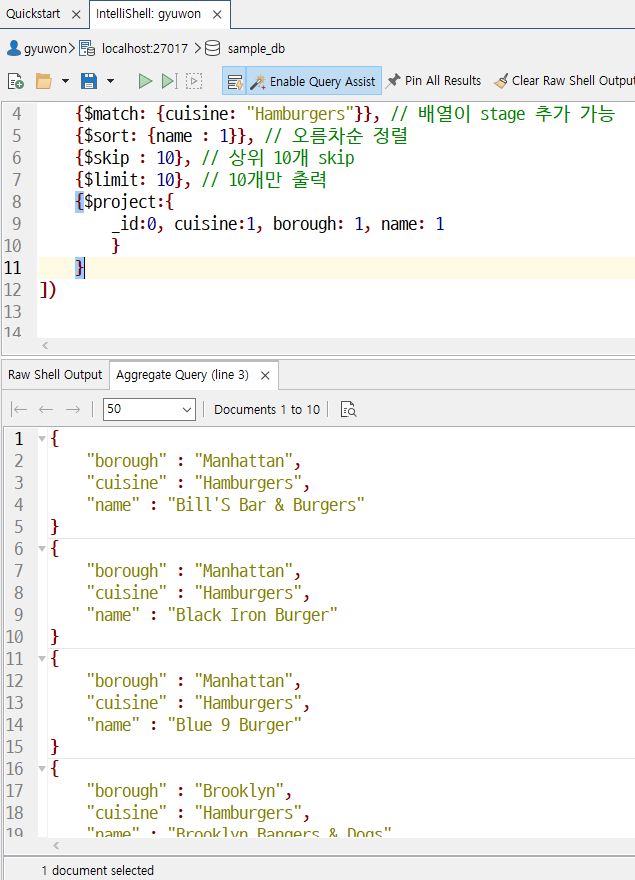


unwind 집계 파이프라인에서 배열 필드로 작업할 때는 종종 하나 이상의 전개단계를 포함해야한다.
이를 통해 지정된 배열 필드의 각 요소에 대해 출력 도큐먼트가 하나씩 있는 출력을 생성할 수 있다.
배열 표현식 // 선출 단계에서 배열 표현식을 사용하는 방법
1. 필터 표현식
필터 기준에 따라 배열에서 요소의 부분집합을 선택한다.
$filter 연산자는 배열 필드와 함께 작동하도록 설계됐으며 우리가 제공하는 옵션을 지정한다.
$filter의 첫 번째 옵션은 input이며 단순히 배열을 지정한다.
$$는 작업중인 표현식 내에서 정의된 변수를 참조하는데 사용
as 절은 필터 표현식 내에서 변수를 정의한다.
이 때 변수는 as 절에서 레이블링한 대로 good라는 의미를 가진다.


project가 마지막 항목일거라는 고정관념을 버려라
praise항목에 0번째인거 출력하기

리소스가 많이 소요되므로 권장하지 않음
44개인 것을 확인할 수 있다.

이미 들어있는 데이터가 최신이 마지막으로 정렬되어 있어서
출력할때 0이 가장 최근이고
-1이 가장 마지막이다.
db.restaurants.findOne() 에서 확인가능

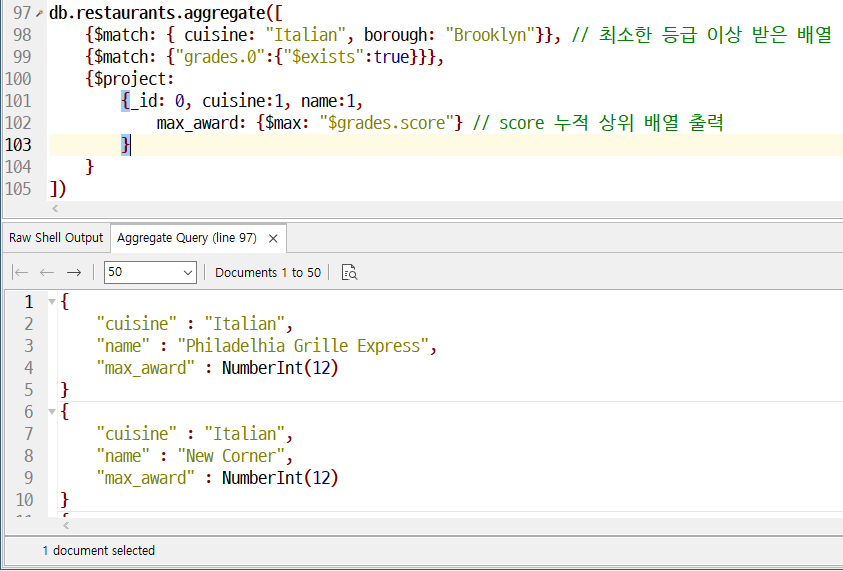
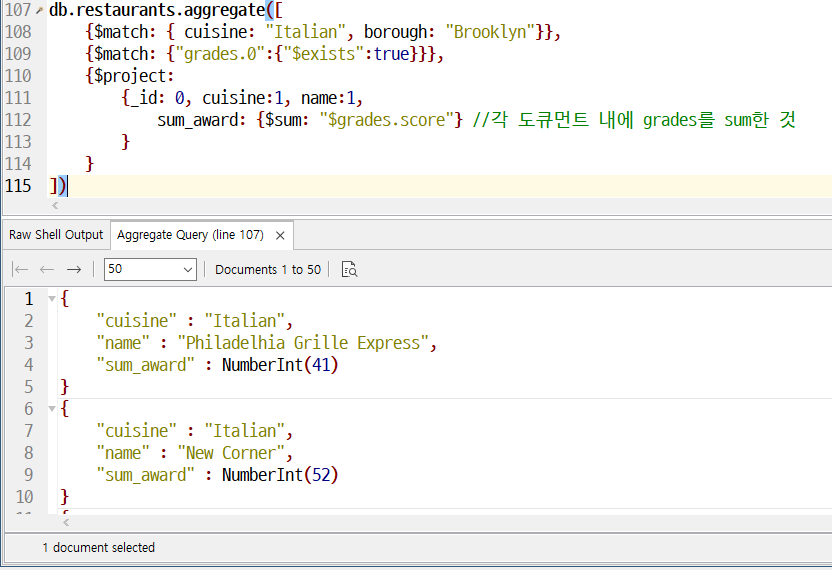
그룹화

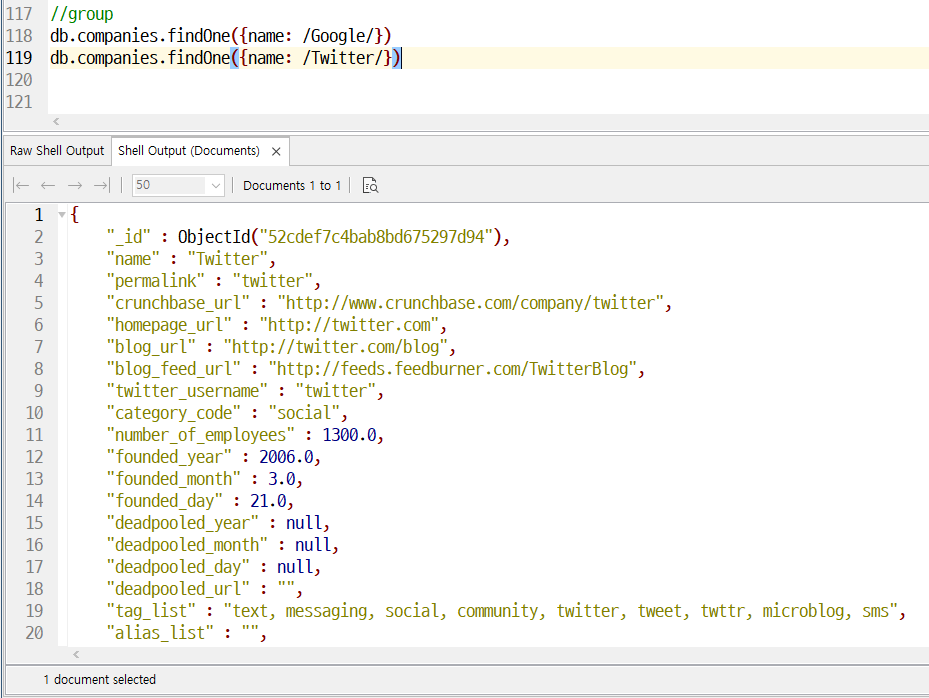
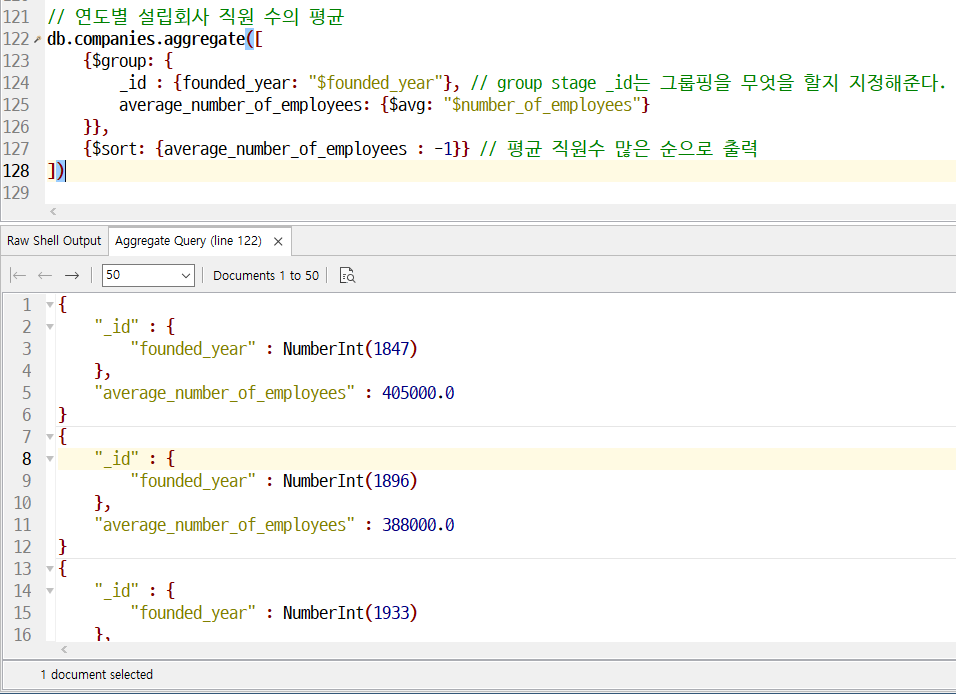
document _id와 다르다. 그룹핑의 _id는 그룹핑을 무엇을 할 지 정해준다.


이렇게 출력된다.


'IT > MongoDB' 카테고리의 다른 글
| [12일차] MongoDB 정리본 (0) | 2022.07.05 |
|---|---|
| [12일차] MongoDB (0) | 2022.07.05 |
| [11일차] MongoDB 정리본 (0) | 2022.07.04 |
| [10일차] MongoDB 정리본 (0) | 2022.07.01 |
| [10일차] MongoDB (0) | 2022.07.01 |




댓글